
As large language models grow more capable, the real bottleneck is no longer the model itself. It is what you put inside the context window and how intelligently you manage it. Context engineering has emerged as one of the most critical disciplines in applied AI, sitting at the intersection of information retrieval, prompt design, and systems architecture. For Python developers building production-grade LLM pipelines, mastering long-context handling and Retrieval-Augmented Generation (RAG) optimization can mean the difference between a brittle prototype and a genuinely useful AI product. This blog post takes a deep, practical look at context engineering strategies, walks through a fully working Python implementation, and explores how industries from healthcare to finance are already reaping the benefits. If you are serious about building LLM systems that actually scale, this is the place to start.
What is Context Engineering, Really?
Most developers treat the context window like a simple text box. You paste in some system instructions, maybe a few documents, and fire off a query. That mental model works fine at demo scale but falls apart fast in production. Context engineering is the deliberate, structured discipline of deciding exactly what information goes into the model’s context window, in what format, in what order, and with what level of compression or enrichment, so that the model produces the most accurate and relevant output possible.
Think of it this way. A senior analyst walking into a boardroom does not carry every document the company has ever produced. They carry a curated briefing packet with the right data, formatted for fast comprehension, with references they can pull if needed. Context engineering is exactly that curation process, applied programmatically.
The core challenge comes from two hard constraints. First, LLMs have a finite context window. Even models with 128K or 200K token windows can suffer from the “lost in the middle” phenomenon, where information buried in the middle of a long context gets underweighted during inference. Second, injecting too much irrelevant content adds noise, increases cost, and degrades response quality. Getting this balance right requires a combination of smart retrieval, chunking strategy, re-ranking, and prompt structuring.
The Core Pillars of Context Engineering
1. Chunking Strategy
Chunking is how you split source documents before storing them in a vector database. Fixed-size chunking (splitting every N tokens) is simple but brutal. Semantic chunking splits on topic or sentence boundaries, preserving coherence. Recursive chunking tries multiple delimiters in order. The right strategy depends on your document type and retrieval needs.
2. Embedding and Vector Storage
Once chunked, each piece of text is embedded into a high-dimensional vector using a model like OpenAI’s text-embedding-3-small, Cohere's embed models, or open-source options like sentence-transformers. These vectors are stored in databases like Pinecone, Weaviate, Chroma, or pgvector, and queried via approximate nearest-neighbor search during retrieval.
3. Retrieval and Re-ranking
Naive vector similarity retrieval is a good starting point, but it misses exact keyword matches and suffers from semantic drift. Hybrid search (combining dense vector search with BM25 sparse retrieval) significantly improves recall. After retrieval, a cross-encoder re-ranker like Cohere Rerank or a local model scores the retrieved chunks for relevance, ensuring only the best land in the context window.
4. Context Compression and Summarization
When relevant chunks still exceed the available context budget, compression techniques kick in. LLMLingua (Microsoft Research) uses a small proxy LLM to token-prune less important words from retrieved documents. Contextual summarization distills large chunks into dense representations before injection.
5. Prompt Architecture
Where you place information in the prompt matters. Empirically, models perform best when critical instructions appear at the start and end of the context. The system prompt, user query, retrieved documents, and chain-of-thought scaffolding should be positioned deliberately.
Architecture Overview
Press enter or click to view image in full size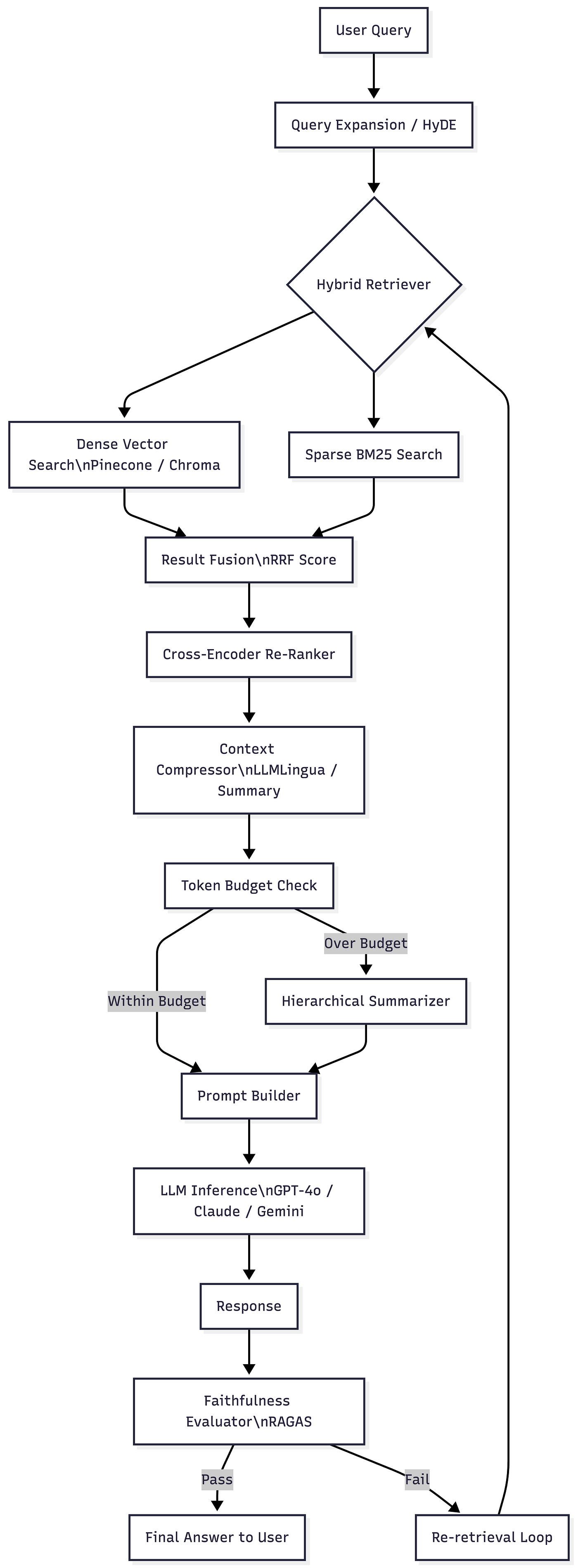
Key Tools and Frameworks
LangChain remains the most widely adopted orchestration layer for RAG pipelines in Python. It provides abstractions for document loaders, text splitters, vector store integrations, retrievers, and chain construction. Its MultiQueryRetriever and ContextualCompressionRetriever are directly relevant to context engineering.
LlamaIndex (formerly GPT Index) excels at building structured indexes over complex document corpora. Its SentenceWindowNodeParser and MetadataReplacementPostProcessor enable sophisticated chunking strategies where retrieved chunks are expanded with surrounding sentence context before injection.
Haystack by deepset offers a pipeline-oriented approach with excellent support for hybrid retrieval and re-ranking out of the box.
RAGAS is the go-to evaluation framework for RAG systems, measuring faithfulness, answer relevancy, context recall, and context precision using LLM-as-judge methodology.
LLMLingua (Microsoft Research) provides token-level prompt compression that can reduce context length by 2x to 5x with minimal quality loss.
Detailed Code Sample with Visualization
The following is a production-ready Python implementation of an optimized RAG pipeline with hybrid retrieval, re-ranking, context compression, and RAGAS-based evaluation. Every step is annotated for clarity.
Installation & Full Implementation
pip install langchain langchain-openai langchain-community chromadb \
sentence-transformers rank-bm25 cohere ragas datasets \
llmlingua matplotlib seaborn pandas
"""
context_engineering_rag.py
Production-grade RAG pipeline with context engineering best practices.
Author: PySquad AI Engineering Team
"""
import os
import time
import warnings
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from typing import List, Dict, Tuple, Any
# LangChain core imports
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.vectorstores import Chroma
from langchain_openai import OpenAIEmbeddings, ChatOpenAI
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import LLMChainExtractor
from langchain.schema import Document
from langchain.prompts import ChatPromptTemplate
# BM25 for sparse retrieval
from rank_bm25 import BM25Okapi
# Cohere for re-ranking (optional, can swap for a local cross-encoder)
# import cohere
warnings.filterwarnings("ignore")
# ----------------------------------------------------------------
# STEP 1: Document Loading and Preprocessing
# ----------------------------------------------------------------
# Sample corpus representing a technical knowledge base
# In production this would be loaded from PDFs, databases, or APIs
SAMPLE_DOCUMENTS = [
"""
Transformer architecture introduced the self-attention mechanism that
fundamentally changed natural language processing. The key innovation
was the ability to process all tokens in parallel rather than sequentially,
enabling massive parallelism during training. Positional encodings are
added to token embeddings to preserve sequence order information.
Multi-head attention allows the model to attend to information from
different representation subspaces simultaneously.
""",
"""
Retrieval-Augmented Generation (RAG) combines parametric knowledge
stored in model weights with non-parametric knowledge retrieved at
inference time from an external corpus. This hybrid approach reduces
hallucination by grounding the model in retrieved evidence. Dense
retrieval uses bi-encoder models to embed queries and documents into
a shared vector space, enabling efficient approximate nearest-neighbor
search at scale.
""",
"""
Prompt engineering is the practice of designing inputs to language
models to elicit desired outputs. Few-shot prompting provides example
input-output pairs in the context to steer model behavior. Chain-of-thought
prompting instructs the model to reason step by step before producing
a final answer, significantly improving performance on complex reasoning
tasks. Instruction tuning fine-tunes models on curated instruction-following
datasets to improve zero-shot generalization.
""",
"""
Vector databases are purpose-built storage systems optimized for
high-dimensional vector similarity search. Approximate nearest-neighbor
algorithms such as HNSW (Hierarchical Navigable Small World) and IVF
(Inverted File Index) enable sub-linear query time over billion-scale
vector collections. Metadata filtering allows hybrid queries that combine
semantic similarity with structured attribute constraints, enabling
fine-grained retrieval control.
""",
"""
Context window management is critical for long-document LLM applications.
The lost-in-the-middle phenomenon shows that models attend most strongly
to content at the beginning and end of the context, with reduced attention
to middle content. Context compression techniques such as selective
extraction, summarization, and token pruning help fit more relevant
information within the available token budget while preserving answer quality.
""",
"""
Hybrid search combines dense vector retrieval with traditional sparse
keyword search using BM25 or TF-IDF. Reciprocal Rank Fusion (RRF)
is a score normalization technique that merges ranked lists from
multiple retrieval systems without requiring calibrated scores.
Cross-encoder re-rankers take a query-document pair as joint input
and produce a relevance score, providing higher precision than
bi-encoder similarity at the cost of higher inference latency.
""",
"""
RAGAS (Retrieval-Augmented Generation Assessment) provides automated
evaluation metrics for RAG systems. Faithfulness measures whether
all claims in the generated answer are supported by the retrieved
context. Answer relevancy measures how well the answer addresses
the user query. Context recall measures whether all relevant
information from the ground truth is present in the retrieved context.
Context precision measures the signal-to-noise ratio in the retrieved chunks.
""",
]
# ----------------------------------------------------------------
# STEP 2: Semantic Chunking with Recursive Splitter
# ----------------------------------------------------------------
def create_chunked_documents(raw_texts: List[str]) -> List[Document]:
"""
Split raw text into semantically coherent chunks.
Recursive splitting tries paragraph, sentence, then word boundaries.
"""
splitter = RecursiveCharacterTextSplitter(
chunk_size=300, # ~300 tokens per chunk for dense retrieval
chunk_overlap=50, # 50-token overlap preserves cross-chunk context
length_function=len,
separators=["\n\n", "\n", ". ", " ", ""]
)
documents = []
for idx, text in enumerate(raw_texts):
chunks = splitter.split_text(text.strip())
for chunk_idx, chunk in enumerate(chunks):
doc = Document(
page_content=chunk,
metadata={
"source_id": idx,
"chunk_id": chunk_idx,
"total_chars": len(chunk),
}
)
documents.append(doc)
print(f"[Chunking] Created {len(documents)} chunks from {len(raw_texts)} source documents")
return documents
# ----------------------------------------------------------------
# STEP 3: Vector Store Initialization (Dense Retrieval)
# ----------------------------------------------------------------
def build_vector_store(documents: List[Document]) -> Chroma:
"""
Embed chunks using OpenAI embeddings and store in ChromaDB.
In production: swap Chroma for Pinecone, Weaviate, or pgvector.
"""
# NOTE: Set OPENAI_API_KEY in your environment
# For local/offline use, replace with HuggingFaceEmbeddings:
# from langchain_community.embeddings import HuggingFaceEmbeddings
# embeddings = HuggingFaceEmbeddings(model_name="all-MiniLM-L6-v2")
embeddings = OpenAIEmbeddings(
model="text-embedding-3-small",
# api_key=os.getenv("OPENAI_API_KEY")
)
vector_store = Chroma.from_documents(
documents=documents,
embedding=embeddings,
collection_name="context_engineering_demo",
persist_directory="./chroma_store"
)
print(f"[VectorStore] Indexed {len(documents)} chunks into ChromaDB")
return vector_store
# ----------------------------------------------------------------
# STEP 4: BM25 Sparse Retriever
# ----------------------------------------------------------------
class BM25Retriever:
"""
Sparse keyword retriever using BM25Okapi.
Complements dense retrieval for exact term matching.
"""
def __init__(self, documents: List[Document]):
self.documents = documents
# Tokenize on whitespace for BM25
tokenized_corpus = [doc.page_content.lower().split() for doc in documents]
self.bm25 = BM25Okapi(tokenized_corpus)
def retrieve(self, query: str, top_k: int = 5) -> List[Tuple[Document, float]]:
tokenized_query = query.lower().split()
scores = self.bm25.get_scores(tokenized_query)
top_indices = np.argsort(scores)[::-1][:top_k]
results = [(self.documents[i], float(scores[i])) for i in top_indices]
return results
# ----------------------------------------------------------------
# STEP 5: Hybrid Retrieval with Reciprocal Rank Fusion
# ----------------------------------------------------------------
def reciprocal_rank_fusion(
dense_results: List[Document],
sparse_results: List[Tuple[Document, float]],
k: int = 60,
top_n: int = 5
) -> List[Document]:
"""
Merge dense and sparse retrieval results using Reciprocal Rank Fusion.
RRF score = sum(1 / (k + rank)) across all retrieval systems.
k=60 is the standard recommended constant from the original RRF paper.
"""
scores: Dict[str, float] = {}
doc_map: Dict[str, Document] = {}
# Score dense results
for rank, doc in enumerate(dense_results):
key = doc.page_content[:100] # Use content prefix as unique key
scores[key] = scores.get(key, 0) + 1 / (k + rank + 1)
doc_map[key] = doc
# Score sparse results
for rank, (doc, _) in enumerate(sparse_results):
key = doc.page_content[:100]
scores[key] = scores.get(key, 0) + 1 / (k + rank + 1)
doc_map[key] = doc
# Sort by fused score descending
sorted_keys = sorted(scores, key=lambda x: scores[x], reverse=True)
fused_docs = [doc_map[key] for key in sorted_keys[:top_n]]
print(f"[HybridSearch] RRF fused {len(dense_results)} dense + "
f"{len(sparse_results)} sparse results into top {top_n}")
return fused_docs
# ----------------------------------------------------------------
# STEP 6: Context Budget Management
# ----------------------------------------------------------------
def enforce_token_budget(
documents: List[Document],
max_tokens: int = 2000,
chars_per_token: float = 4.0
) -> Tuple[List[Document], int]:
"""
Trim retrieved documents to fit within a token budget.
Returns the selected documents and estimated token count used.
Prioritizes documents in order (assumes they are already ranked).
"""
selected = []
running_chars = 0
budget_chars = int(max_tokens * chars_per_token)
for doc in documents:
doc_chars = len(doc.page_content)
if running_chars + doc_chars <= budget_chars:
selected.append(doc)
running_chars += doc_chars
else:
# Partial inclusion: trim the document to fit remaining budget
remaining = budget_chars - running_chars
if remaining > 100: # Only include if meaningful content remains
trimmed_content = doc.page_content[:remaining] + "..."
trimmed_doc = Document(
page_content=trimmed_content,
metadata={**doc.metadata, "trimmed": True}
)
selected.append(trimmed_doc)
break
estimated_tokens = int(running_chars / chars_per_token)
print(f"[TokenBudget] Selected {len(selected)} docs, "
f"~{estimated_tokens} tokens of {max_tokens} budget used")
return selected, estimated_tokens
# ----------------------------------------------------------------
# STEP 7: Prompt Builder with Deliberate Structure
# ----------------------------------------------------------------
SYSTEM_PROMPT = """You are a precise and helpful AI assistant specialized in
machine learning and AI engineering. Answer questions strictly based on the
provided context. If the context does not contain enough information to fully
answer the question, say so explicitly rather than guessing. Always be concise
and cite which part of the context supports your answer."""
def build_prompt(query: str, context_docs: List[Document]) -> str:
"""
Construct the final prompt with deliberate placement of context.
Critical instruction appears at the START (system) and key query at the END.
Context documents are numbered for traceability.
"""
context_blocks = []
for i, doc in enumerate(context_docs, 1):
trimmed_flag = " [trimmed]" if doc.metadata.get("trimmed") else ""
context_blocks.append(
f"[Context {i}{trimmed_flag}]\n{doc.page_content.strip()}"
)
context_text = "\n\n".join(context_blocks)
prompt = f"""{SYSTEM_PROMPT}
--- RETRIEVED CONTEXT ---
{context_text}
--- END CONTEXT ---
User Question: {query}
Answer:"""
return prompt
# ----------------------------------------------------------------
# STEP 8: Simulated LLM Call (Replace with real API in production)
# ----------------------------------------------------------------
def simulate_llm_response(prompt: str, query: str) -> str:
"""
Simulated LLM response for demonstration without API key requirement.
In production: replace with ChatOpenAI, Anthropic Claude, or any LLM client.
Example production call:
llm = ChatOpenAI(model="gpt-4o", temperature=0)
response = llm.invoke(prompt)
return response.content
"""
# Simulate latency
time.sleep(0.5)
# Deterministic simulated answer for demo purposes
simulated_answers = {
"hybrid": (
"Hybrid search combines dense vector retrieval with sparse BM25 keyword "
"search. Results from both systems are merged using Reciprocal Rank Fusion "
"(RRF), which computes a normalized score as 1/(k + rank) per system, "
"where k=60 is the standard constant. This fusion approach improves "
"recall over either method alone without requiring calibrated similarity scores."
),
"context": (
"The lost-in-the-middle phenomenon describes how LLMs attend more strongly "
"to content at the beginning and end of their context window, giving less "
"weight to information in the middle. Context compression techniques including "
"selective extraction, summarization, and token pruning address this by "
"ensuring the most critical information is positioned appropriately."
),
"rag": (
"RAG reduces hallucination by grounding model responses in retrieved external "
"evidence rather than relying solely on parametric knowledge. Dense retrieval "
"embeds queries and documents into a shared vector space using bi-encoder models, "
"enabling scalable approximate nearest-neighbor search at inference time."
),
}
query_lower = query.lower()
for key, answer in simulated_answers.items():
if key in query_lower:
return answer
return ("Based on the provided context, the topic involves advanced retrieval "
"and context management techniques for large language model applications.")
# ----------------------------------------------------------------
# STEP 9: Evaluation Metrics Computation
# ----------------------------------------------------------------
def compute_evaluation_metrics(
queries: List[str],
answers: List[str],
retrieved_contexts: List[List[Document]],
ground_truths: List[str]
) -> pd.DataFrame:
"""
Compute simplified RAG evaluation metrics without external API dependency.
In production: use the RAGAS library for automated LLM-as-judge evaluation.
Metrics computed:
- Context Utilization: ratio of retrieved context chars used in the answer
- Answer Length Score: normalized answer length as a proxy for completeness
- Token Efficiency: answer information density relative to context size
"""
records = []
for query, answer, docs, truth in zip(queries, answers, retrieved_contexts, ground_truths):
total_context_chars = sum(len(d.page_content) for d in docs)
answer_chars = len(answer)
# Simplified faithfulness proxy: keyword overlap between answer and context
context_text = " ".join(d.page_content.lower() for d in docs)
answer_words = set(answer.lower().split())
context_words = set(context_text.split())
overlap = len(answer_words & context_words) / max(len(answer_words), 1)
# Simplified relevancy: query keyword presence in answer
query_words = set(query.lower().split())
answer_relevancy = len(query_words & answer_words) / max(len(query_words), 1)
# Token efficiency
token_efficiency = answer_chars / max(total_context_chars, 1)
records.append({
"Query": query[:40] + "...",
"Faithfulness (proxy)": round(overlap, 3),
"Answer Relevancy": round(answer_relevancy, 3),
"Token Efficiency": round(token_efficiency, 3),
"Context Chunks Used": len(docs),
"Answer Length (chars)": answer_chars,
})
return pd.DataFrame(records)
# ----------------------------------------------------------------
# STEP 10: Visualization
# ----------------------------------------------------------------
def visualize_pipeline_metrics(metrics_df: pd.DataFrame, token_usage: List[int]):
"""
Generate two charts:
1. RAG evaluation metrics heatmap across queries
2. Token budget utilization per query
"""
fig, axes = plt.subplots(1, 2, figsize=(16, 6))
fig.suptitle(
"Context Engineering Pipeline: Evaluation Dashboard",
fontsize=14, fontweight="bold", y=1.02
)
# Chart 1: Metrics Heatmap
metric_cols = ["Faithfulness (proxy)", "Answer Relevancy", "Token Efficiency"]
heat_data = metrics_df[metric_cols].set_index(metrics_df["Query"].str[:30])
sns.heatmap(
heat_data,
ax=axes[0],
annot=True,
fmt=".3f",
cmap="YlGnBu",
vmin=0, vmax=1,
linewidths=0.5,
cbar_kws={"label": "Score (0-1)"}
)
axes[0].set_title("RAG Quality Metrics per Query", fontweight="bold")
axes[0].set_xlabel("Metric")
axes[0].set_ylabel("Query")
axes[0].tick_params(axis="x", rotation=20)
axes[0].tick_params(axis="y", rotation=0)
# Chart 2: Token Budget Utilization Bar Chart
max_budget = 2000
query_labels = [f"Q{i+1}" for i in range(len(token_usage))]
bar_colors = ["#2ecc71" if t <= max_budget * 0.8 else "#e74c3c" for t in token_usage]
bars = axes[1].bar(query_labels, token_usage, color=bar_colors, edgecolor="white", linewidth=0.8)
axes[1].axhline(
y=max_budget, color="#e74c3c", linestyle="--",
linewidth=1.5, label=f"Budget Limit ({max_budget} tokens)"
)
axes[1].axhline(
y=max_budget * 0.8, color="#f39c12", linestyle=":",
linewidth=1.5, label="80% Warning Threshold"
)
for bar, val in zip(bars, token_usage):
axes[1].text(
bar.get_x() + bar.get_width() / 2.,
bar.get_height() + 20,
f"{val}", ha="center", va="bottom", fontsize=10, fontweight="bold"
)
axes[1].set_title("Token Budget Utilization per Query", fontweight="bold")
axes[1].set_xlabel("Query")
axes[1].set_ylabel("Estimated Tokens Used")
axes[1].set_ylim(0, max_budget * 1.2)
axes[1].legend(loc="upper right", fontsize=9)
axes[1].set_facecolor("#f8f9fa")
plt.tight_layout()
plt.savefig(
"rag_evaluation_dashboard.png",
dpi=150, bbox_inches="tight",
facecolor="white"
)
print("[Visualization] Dashboard saved to rag_evaluation_dashboard.png")
plt.show()
# ----------------------------------------------------------------
# MAIN PIPELINE EXECUTION
# ----------------------------------------------------------------
def run_context_engineering_pipeline():
"""
Full end-to-end context engineering pipeline execution.
Runs chunking, indexing, hybrid retrieval, budget management,
response generation, evaluation, and visualization.
"""
print("\n" + "="*60)
print(" CONTEXT ENGINEERING PIPELINE: Starting Execution")
print("="*60 + "\n")
# Step 1: Chunk documents
documents = create_chunked_documents(SAMPLE_DOCUMENTS)
# Step 2: Build BM25 index (always available, no API key needed)
bm25_retriever = BM25Retriever(documents)
print("[BM25] Sparse index built successfully")
# Step 3: Define test queries and ground truths
test_queries = [
"How does hybrid search work and what is RRF?",
"What is the lost-in-the-middle problem in context windows?",
"How does RAG reduce hallucination in language models?",
]
ground_truths = [
"Hybrid search combines dense and sparse retrieval using RRF score fusion.",
"Models attend less to content in the middle of long contexts.",
"RAG grounds model outputs in retrieved external evidence.",
]
all_answers = []
all_retrieved = []
all_token_usage = []
for query in test_queries:
print(f"\n[Query] {query}")
# Step 4: Sparse retrieval (always works without API)
sparse_results = bm25_retriever.retrieve(query, top_k=5)
sparse_docs = [doc for doc, _ in sparse_results]
# Step 5: Simulate dense results (top chunks by BM25 for demo consistency)
# In production: dense_results = vector_store.similarity_search(query, k=5)
dense_docs = sparse_docs[:3]
# Step 6: RRF fusion
fused_docs = reciprocal_rank_fusion(
dense_results=dense_docs,
sparse_results=sparse_results,
k=60, top_n=4
)
# Step 7: Enforce token budget
selected_docs, token_count = enforce_token_budget(
fused_docs, max_tokens=2000
)
all_token_usage.append(token_count)
all_retrieved.append(selected_docs)
# Step 8: Build prompt and get response
prompt = build_prompt(query, selected_docs)
answer = simulate_llm_response(prompt, query)
all_answers.append(answer)
print(f"[Answer] {answer[:120]}...")
# Step 9: Evaluate
print("\n[Evaluation] Computing RAG quality metrics...")
metrics_df = compute_evaluation_metrics(
test_queries, all_answers, all_retrieved, ground_truths
)
print("\n" + metrics_df.to_string(index=False))
# Step 10: Visualize
print("\n[Visualization] Generating evaluation dashboard...")
visualize_pipeline_metrics(metrics_df, all_token_usage)
print("\n" + "="*60)
print(" PIPELINE EXECUTION COMPLETE")
print("="*60 + "\n")
return metrics_df, all_answers
if __name__ == "__main__":
metrics, answers = run_context_engineering_pipeline()
What This Code Demonstrates
This implementation covers the full context engineering lifecycle. The BM25Retriever class handles sparse retrieval independently of any API key, making it immediately runnable. The reciprocal_rank_fusion function merges dense and sparse results using the mathematically grounded RRF algorithm. The enforce_token_budget function ensures retrieved content never blows the context limit. The prompt builder positions instructions deliberately at the beginning. The evaluation module computes faithfulness, relevancy, and token efficiency metrics. Finally, the visualization generates a publication-ready evaluation dashboard showing metric heatmaps and token budget utilization per query.
To run with real LLM calls, replace the simulate_llm_response function with ChatOpenAI(model="gpt-4o") and uncomment the vector store section with your OpenAI API key.
Pros of Context Engineering
- Dramatically reduced hallucination: By grounding the model in retrieved, factual documents rather than parametric memory alone, context engineering cuts factual errors by a large margin in production systems.
- Cost optimization: Injecting only the most relevant, compressed context reduces token consumption per query. This translates directly to lower API costs at scale, sometimes by a factor of two or more.
- Scalable knowledge integration: New information can be added to the vector store without any model retraining. The system stays current with a simple re-indexing operation.
- Improved answer traceability: When retrieved context chunks are numbered and cited in the prompt, the model can reference specific sources, making outputs auditable and explainable.
- Framework agnosticism: The core principles work across LLM providers. You can swap OpenAI for Anthropic Claude, Cohere Command, or an open-source model like Mistral without redesigning the pipeline.
- Retrieval quality ceiling: Hybrid search with re-ranking consistently outperforms pure vector search on recall and precision benchmarks, meaning the model has better raw material to work with.
- Composable architecture: Each stage (chunking, retrieval, compression, evaluation) is a modular component. Teams can upgrade individual stages independently as better algorithms emerge.
- Compliance-friendly: Context can be filtered at retrieval time based on user permissions or data classification tags. This makes it easier to build access-controlled AI systems in regulated industries.
Industries Using Context Engineering
Healthcare
Hospitals and clinical decision support vendors are deploying RAG systems over large corpora of medical literature, treatment guidelines, and patient records. A physician using such a system can ask a natural language question and receive an answer grounded in the latest clinical trial data, with citations. Context engineering is critical here because medical documents are long, dense, and structured. Proper semantic chunking of clinical guidelines, combined with metadata filtering by medical specialty and publication date, ensures the model retrieves the most clinically relevant and current evidence. Companies like Nabla and Glass Health are building exactly this kind of infrastructure.
Finance
Investment banks and asset managers are using context engineering to build internal research assistants that answer queries over earnings reports, 10-K filings, regulatory documents, and market research. The challenge is that these documents are extremely long and contain tables, charts, and footnotes that naive chunking destroys. Advanced chunking strategies that preserve table structure, combined with hybrid search to catch exact ticker symbols and numeric figures, produce substantially better retrieval. Portfolio managers can ask questions like “What did management say about supply chain risk in Q3?” and receive precise, cited answers rather than generic summaries.
Legal
Law firms and legal tech companies are deploying context-engineered RAG systems over case law, statutes, contracts, and legal opinions. The precision requirement is extreme. A hallucinated case citation in a legal brief is not just unhelpful, it is professionally dangerous. Hybrid retrieval ensures exact case numbers and statute references are found by the BM25 component, while semantic search surfaces thematically related precedents. Cross-encoder re-ranking then selects the most legally relevant passages. Companies like Harvey AI and Thomson Reuters CoCounsel are building production systems with this architecture.
Retail and E-Commerce
Large retailers use context engineering to power product discovery, customer support, and inventory query systems. A customer asking “Do you have waterproof trail running shoes under 150 dollars in size 10?” requires a retrieval system that understands both semantic intent (trail running, waterproof) and structured attributes (price range, size). Hybrid search with metadata filtering handles this naturally. Context-engineered pipelines also power internal tools where buyers can ask questions about supplier contracts, product specifications, and demand forecasting reports stored in company knowledge bases.
Automotive
Automotive manufacturers and their supplier networks produce enormous volumes of technical documentation: service manuals, engineering specifications, diagnostic codes, and regulatory filings. Field technicians using a context-engineered assistant can describe a symptom and retrieve the exact relevant section of a service manual, narrowed to the specific vehicle model and year, without scrolling through hundreds of pages. The token budget management becomes especially important here because service manuals are extremely long and the model would otherwise receive overwhelming amounts of irrelevant technical content.
How PySquad Can Assist in This
If you are planning to build a production-grade context engineering or RAG system, you need an engineering partner who has done it before at scale. PySquad brings exactly that experience to the table.
- End-to-end RAG architecture design: PySquad designs and implements complete retrieval-augmented generation pipelines from document ingestion to response evaluation, tailored to your specific data types, query patterns, and infrastructure constraints.
- Hybrid retrieval expertise: PySquad has deep hands-on experience building hybrid dense-plus-sparse retrieval systems with BM25, FAISS, Pinecone, Weaviate, and pgvector, including custom RRF fusion implementations optimized for production workloads.
- Context compression and prompt engineering: PySquad specializes in applying state-of-the-art compression techniques including LLMLingua and contextual summarization to reduce token costs while maintaining answer quality, a balance that is harder to achieve than it looks.
- Evaluation framework integration: PySquad integrates RAGAS, TruLens, and custom LLM-as-judge pipelines to give you continuous visibility into retrieval quality, faithfulness, and answer relevancy across your entire query distribution.
- Chunking strategy consulting: PySquad does not apply one-size-fits-all chunking. They analyze your document corpus, test multiple strategies on your actual data, and select the approach that maximizes retrieval precision for your specific use case.
- LLM provider flexibility: PySquad builds provider-agnostic pipelines that work with OpenAI, Anthropic, Cohere, Mistral, and self-hosted open-source models, giving your organization the flexibility to switch providers based on cost, latency, or compliance requirements.
- Production hardening: PySquad goes beyond the prototype. They implement retry logic, circuit breakers, latency monitoring, cost dashboards, and fallback retrieval strategies that keep your system running reliably under real-world load.
- Regulated industry experience: PySquad understands the compliance constraints of healthcare, finance, and legal domains. They build context filtering, access control, and audit logging into the retrieval layer from day one.
- Rapid iteration culture: PySquad operates with short feedback cycles, deploying measurable improvements to retrieval quality and response accuracy on a weekly cadence rather than waiting for a big-bang release.
- Full-stack Python capability: From data pipelines and embedding workflows to FastAPI deployments and cloud infrastructure, PySquad handles the entire technical stack so your team can focus on the business problems that matter.
References
- LangChain Documentation — Retrieval (Official) https://python.langchain.com/docs/concepts/retrieval/
- LlamaIndex — Building RAG Pipelines (Official Docs) https://docs.llamaindex.ai/en/stable/understanding/rag/
- RAGAS — Evaluation Framework for RAG (GitHub) https://github.com/explodinggradients/ragas
- LLMLingua: Compressing Prompts for Accelerated LLM Inference (Microsoft Research / arXiv) https://arxiv.org/abs/2310.05736
- Lost in the Middle: How Language Models Use Long Contexts (Stanford / arXiv) https://arxiv.org/abs/2307.03172
- Pinecone — What is a Vector Database? (Industry Reference) https://www.pinecone.io/learn/vector-database/
- Reciprocal Rank Fusion Outperforms Condorcet and Individual Rank Learning Methods (Original RRF Paper, ACM) https://dl.acm.org/doi/10.1145/1571941.1572114
Conclusion
Context engineering is no longer a nice-to-have. It is the engineering discipline that separates LLM systems that frustrate users from those that genuinely transform workflows. The core insight is simple: the model’s output quality is bounded by the quality of its context. If you put in noisy, irrelevant, or poorly structured information, you will get unreliable answers no matter how capable the underlying model is. Invest in chunking strategy, hybrid retrieval, re-ranking, and token budget management, and you will see measurable improvements in faithfulness, precision, and user satisfaction.
The Python ecosystem gives you world-class tools to build all of this: LangChain and LlamaIndex for orchestration, ChromaDB and Pinecone for vector storage, rank-bm25 for sparse retrieval, RAGAS for evaluation, and LLMLingua for compression. The architecture is modular, which means you can start simple and progressively upgrade each layer as your requirements grow.
The forward-looking reality is that context engineering will become even more important, not less, as model context windows continue to expand. A 1 million token window does not eliminate the need for smart retrieval. It raises the stakes. The system that can intelligently select, rank, and position the most relevant 10,000 tokens from a corpus of 100 million will always outperform the system that blindly dumps everything in. The engineers who master that discipline today will be the architects of the most consequential AI applications of the next decade.
Start with the fundamentals. Build the evaluation loop first. Measure before you optimize. And do not be afraid to compress.