
Multimodal foundation models are redefining how AI systems understand and interact with the world by combining vision, audio, and text into a unified intelligence layer. From voice assistants that interpret tone to applications that analyze images and generate contextual responses, the demand for multimodal AI is growing rapidly across industries. With the rise of frameworks like Hugging Face Transformers, developers can now build powerful multimodal pipelines in Python without needing massive infrastructure. This blog explores how to design and implement multimodal systems that process diverse data types seamlessly. You will learn practical techniques to integrate vision, speech, and language models, understand their architecture, and build real-world applications that move beyond single modality AI into truly intelligent systems.
What are Multimodal Foundation Models
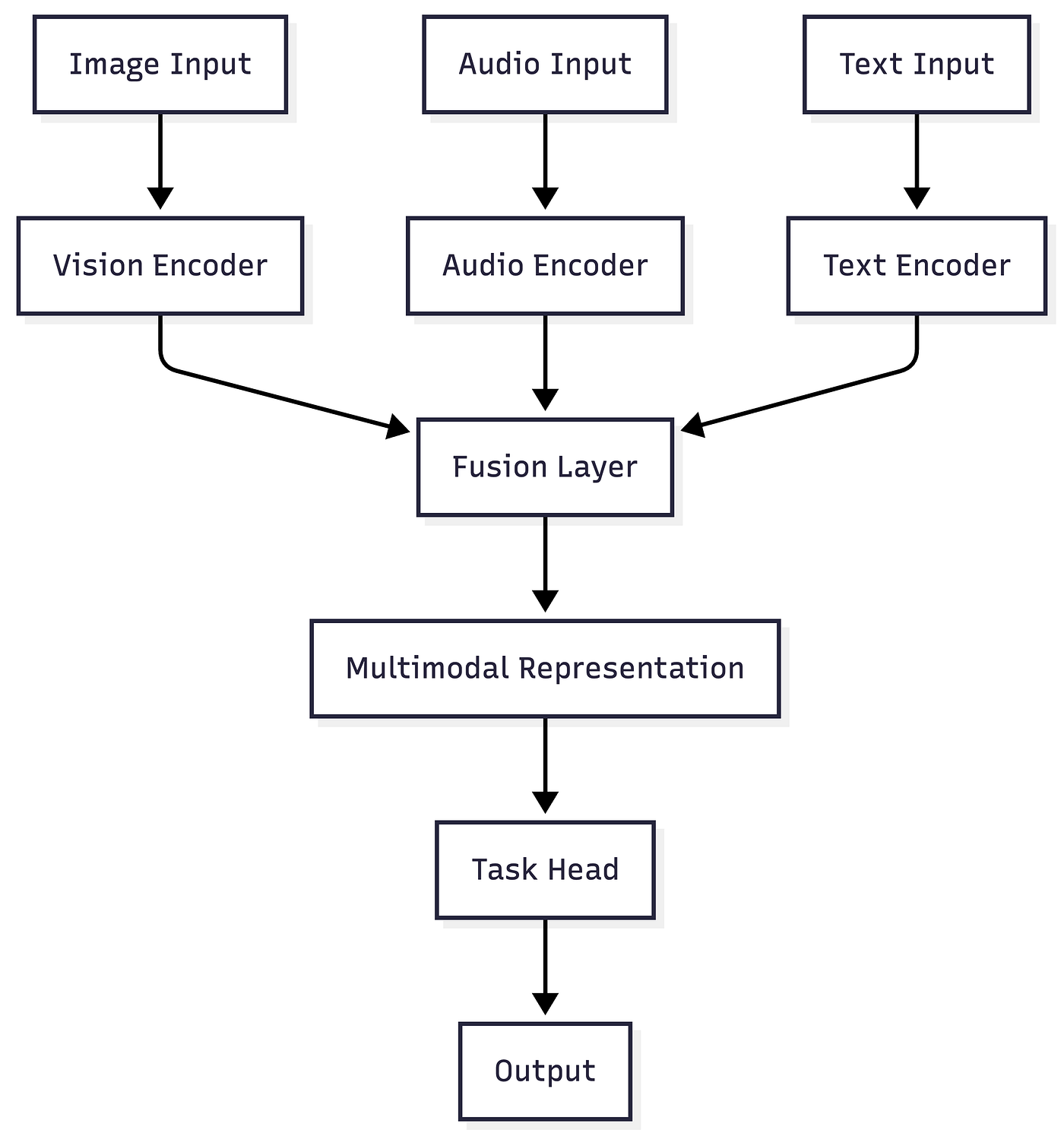
Multimodal models are trained to process and reason across different data types such as:
- Images
- Audio
- Text
Instead of treating these inputs independently, they learn a shared representation space. This allows the model to connect visual context with language, or speech with semantics.
For example:
- Image plus text input produces a caption or answer
- Audio input gets transcribed and analyzed for sentiment
- Combined inputs enable richer decision making
Core Concept
At a technical level, multimodal systems rely on:
- Encoders for each modality such as CNNs for vision, transformers for text, spectrogram based encoders for audio
- A fusion mechanism to combine embeddings
- A decoder or head for task specific outputs
Key Tools and Frameworks
Hugging Face Transformers
Provides pretrained multimodal models such as:
- CLIP for image text alignment
- Whisper for speech recognition
- Vision Encoder Decoder models for captioning
PySyft
Enables privacy preserving multimodal training across distributed environments.
LangChain
Useful for building pipelines that integrate multimodal outputs into downstream LLM workflows.
Knowledge Graphs
Enhance multimodal reasoning by connecting extracted entities across modalities.
Functionality Breakdown
- Input Processing: Each modality is preprocessed independently
- Feature Extraction: Encoders convert raw data into embeddings
- Fusion: Embeddings are combined using attention mechanisms
- Task Execution: Output head performs classification, generation, or reasoning
Real World Applicability
- Visual question answering systems
- Speech enabled assistants
- Content moderation across media types
- Autonomous systems combining sensor and language input
Detailed Code Sample with Visualization
Below is a practical Python implementation using Hugging Face to combine image captioning and speech transcription into a unified pipeline.
Step 1: Install Dependencies
pip install transformers torch pillow librosa matplotlib soundfile
Step 2: Multimodal Pipeline Code
from transformers import pipeline
from PIL import Image
import librosa
import matplotlib.pyplot as plt
import numpy as np
# Load pipelines
image_captioner = pipeline("image-to-text", model="Salesforce/blip-image-captioning-base")
speech_recognizer = pipeline("automatic-speech-recognition", model="openai/whisper-base")
# Load image
image = Image.open("sample.jpg")
# Generate caption
caption_result = image_captioner(image)
caption = caption_result[0]["generated_text"]
# Load audio
audio, sr = librosa.load("sample.wav", sr=16000)
# Transcribe audio
transcription = speech_recognizer(audio)["text"]
# Combine outputs
final_output = f"Image Caption: {caption}\nAudio Transcription: {transcription}"
print(final_output)
Step 3: Visualization of Audio Signal
plt.figure()
plt.plot(audio)
plt.title("Audio Waveform")
plt.xlabel("Time")
plt.ylabel("Amplitude")
plt.show()
Pros of Multimodal Foundation Models
- Unified Intelligence
- Combines multiple data types for richer insights
- Improved Accuracy
- Cross modality validation reduces errors
- Scalability
- Easily extendable to additional modalities
- Better User Experience
- Enables natural interaction through voice and vision
- Strong Ecosystem
- Hugging Face provides extensive pretrained models and community support
- Real Time Capabilities
- Supports streaming inputs for dynamic applications
Industry Applications
Healthcare
Doctors use multimodal models to analyze medical images along with patient history and voice notes to improve diagnosis accuracy.
Finance
Banks combine voice call analysis with transaction data and text logs to detect fraud patterns more effectively.
Retail
Ecommerce platforms use image recognition and text analysis to improve product recommendations and search relevance.
Automotive
Autonomous vehicles integrate camera feeds, audio cues, and navigation instructions for safer decision making.
Legal
Law firms process audio recordings, scanned documents, and written contracts to extract insights and automate compliance checks.
How PySquad can assist in this
- PySquad delivers end to end multimodal AI solutions tailored to enterprise needs
- PySquad specializes in integrating vision, audio, and text models into unified pipelines
- PySquad ensures optimized deployment of Hugging Face models for production scale
- PySquad provides expertise in building secure and compliant AI systems
- PySquad helps design scalable architectures for multimodal workflows
- PySquad enables seamless integration with existing enterprise data systems
- PySquad offers advanced fine tuning and customization of foundation models
- PySquad supports monitoring, evaluation, and continuous improvement of AI systems
- PySquad accelerates time to market with proven implementation strategies
- PySquad builds robust and explainable AI systems that drive real business value
References
- Hugging Face Transformers Documentation: https://huggingface.co/docs/transformers
- CLIP Model Paper: https://arxiv.org/abs/2103.00020
- Whisper Model Repository: https://github.com/openai/whisper
- BLIP Image Captioning: https://github.com/salesforce/BLIP
Conclusion
Multimodal foundation models are unlocking a new level of intelligence in AI systems by enabling seamless integration of vision, audio, and text. This blog explored how these systems work, how to implement them using Python and Hugging Face, and how they are transforming real world applications across industries.
For developers and organizations, the opportunity is clear. Moving beyond single modality AI is no longer optional if you want to build context aware and human like systems. By leveraging pretrained models and scalable architectures, you can rapidly prototype and deploy powerful multimodal applications.
Looking ahead, multimodal AI will become the default paradigm for intelligent systems. The teams that invest early in building these capabilities will lead the next wave of AI innovation.